Reproducibility 1: figure 2
Benchmark on 3 landscapes:
linear regulation of two genes (see Kemble et al. )
geometric model with Gaussian (see Tenaillon et al.)
regulatory cascade model (see Nghe et al.)
Get True landscape, inferred landscape, phenotype comparison, performance comparison between spectral initialization and without
Load the packages
[2]:
import sys
sys.path.append('../')
from dlim.model import DLIM
from dlim.dataset import Data_model
from dlim.api import DLIM_API
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import pearsonr, spearmanr
from numpy.random import choice, seed
from src_simulate_data.sim_data import Simulated
import torch
torch.manual_seed(0)
[2]:
<torch._C.Generator at 0x7fcc5466b410>
Generate data, define the path to save model
[ ]:
type_f = "cascade"
nb_var = 30
data_simulated = Simulated(nb_var, type_f)
data = Data_model(data=pd.DataFrame(data_simulated.data), n_variables=2)
model_save_path = None
/home/alexandre/Downloads/papers_drafts/flux_project/dlim_revised/D-LIM-model/reproducibility/../src_simulate_data/sim_data.py:12: RuntimeWarning: invalid value encountered in power
return ((M-m)/(1 + power(x/K, n))) + m
Split data into training, testing and validation
[3]:
seed(42)
train_id_all = choice(range(data.data.shape[0]), int(data.data.shape[0]*0.7), replace=False)
train_id = choice(train_id_all, int(len(train_id_all)*0.9), replace=False)
test_id = [i for i in train_id_all if i not in train_id]
val_id = [i for i in range(data.data.shape[0]) if i not in train_id_all]
train_data = data.subset(train_id)
test_data = data.subset(test_id)
val_data = data.subset(val_id)
With spectral initialization
[ ]:
# Define the model: with 1 single hidden layer whose dimension is 32
model = DLIM(n_variables = train_data.nb_val, hid_dim = 32, nb_layer = 0)
dlim_regressor = DLIM_API(model=model, flag_spectral=True)
losses = dlim_regressor.fit(train_data, test_data = None, lr = 1e-3, nb_epoch=300, batch_size=32, emb_regularization=0.001, \
save_path= model_save_path)
# Get the infered fitness, variance and latent representation
fit_a, var_a, lat_a = dlim_regressor.predict(val_data.data[:,:-1], detach=True)
spectral gap = 0.826699435710907
spectral gap = 0.3799635171890259
Without spectralization
[ ]:
# Define the model: with 1 single hidden layer whose dimension is 32
model_no = DLIM(n_variables = train_data.nb_val, hid_dim = 32, nb_layer = 0)
dlim_no = DLIM_API(model=model_no, flag_spectral=False)
losses = dlim_no.fit(train_data, test_data =None, lr = 1e-3, nb_epoch=300, batch_size=32, emb_regularization=0.001, \
save_path= model_save_path)
# Get the infered fitness, variance and latent representation
fit_no, var_no, lat_no = dlim_no.predict(val_data.data[:,:-1], detach=True)
Visualization of the results
Get the original & infered landscapes;
Compare real & infered phenotype;
Compare the performance of using spectralization vs without
[ ]:
score = pearsonr(fit_a.flatten(), val_data.data[:, [-1]].flatten())[0]
print(score)
score_no = pearsonr(fit_no.flatten(), val_data.data[:, [-1]].flatten())[0]
print(score_no)
fig, (ax, bx, cx, dx) = plt.subplots(1, 4, figsize=(8, 2))
# original landscape
data_simulated.plot(ax)
# inferred landscape
dlim_regressor.plot(bx, data)
for xx in [ax, bx, cx, dx]:
for el in ["top", "right"]:
xx.spines[el].set_visible(False)
# Plot infered phenotype vs real phenotype
r1 = spearmanr(dlim_regressor.model.genes_emb[0].detach(), data_simulated.A)[0]
r2 = spearmanr(dlim_regressor.model.genes_emb[1].detach(), data_simulated.B)[0]
print(pearsonr(lat_a[:, 0], val_data[:, -1]))
cx.text(dlim_regressor.model.genes_emb[0].detach().numpy().min(), data_simulated.A.max(), f"$\\rho={r1:.2f}$", c="C0")
cx.text(dlim_regressor.model.genes_emb[1].detach().numpy().min(), data_simulated.A.max() - 1, f"$\\rho={r2:.2f}$", c="C1")
cx.scatter(dlim_regressor.model.genes_emb[0].detach(), data_simulated.A, c="C0", s=3)
cx.scatter(dlim_regressor.model.genes_emb[1].detach(), data_simulated.B, c="C1", s=3)
cx.set_xlabel("$\\varphi_1$ | $\\varphi_2$")
cx.set_ylabel("$\\phi_1$| $\\phi_2$")
# Plot infered fitness vs real fitness (no spectralization)
dx.scatter(val_data.data[:, [-1]].flatten(), fit_no.flatten(), c="grey", s=3)
# Plot infered fitness vs real fitness (with spectralization)
dx.scatter(val_data.data[:, [-1]].flatten(), fit_a.flatten(), c="orange", s=3)
dx.text(val_data.data[:, [-1]].flatten().min(), fit_no.flatten().max(), f"$\\rho={score_no:.2f}$", c="grey")
dx.text(val_data.data[:, [-1]].flatten().min(), fit_a.flatten().max() - 0.6, f"$\\rho={score:.2f}$", c="orange")
dx.set_xlabel("F")
dx.set_ylabel("$\\hat F$")
# plt.suptitle(type_f)
plt.tight_layout()
plt.savefig("./img/fig2_" + str(type_f) + ".png", dpi=300, transparent=True)
plt.show()
0.9886335861203054
0.9277586062322256
PearsonRResult(statistic=0.07436001332601706, pvalue=0.22327047657757326)
/home/alexandre/Downloads/papers_drafts/flux_project/dlim_revised/D-LIM-model/reproducibility/../src_simulate_data/sim_data.py:12: RuntimeWarning: invalid value encountered in power
return ((M-m)/(1 + power(x/K, n))) + m
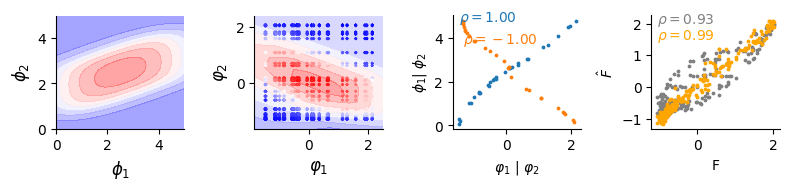
Repeat for geometric model with Gaussian and regulatory Cascade model
Title Gaussian
[ ]:
type_f = "tgaus"
nb_var = 30
data_simulated = Simulated(nb_var, type_f)
data = Data_model(data=pd.DataFrame(data_simulated.data), n_variables=2)
model_save_path = None
seed(42)
train_id_all = choice(range(data.data.shape[0]), int(data.data.shape[0]*0.7), replace=False)
train_id = choice(train_id_all, int(len(train_id_all)*0.9), replace=False)
test_id = [i for i in train_id_all if i not in train_id]
val_id = [i for i in range(data.data.shape[0]) if i not in train_id_all]
train_data = data.subset(train_id)
test_data = data.subset(test_id)
val_data = data.subset(val_id)
model = DLIM(n_variables = train_data.nb_val, hid_dim = 32, nb_layer = 0)
dlim_regressor = DLIM_API(model=model, flag_spectral=True)
losses = dlim_regressor.fit(train_data, test_data, lr = 1e-3, nb_epoch=300, batch_size=32, emb_regularization=0, \
save_path= model_save_path)
fit_a, var_a, lat_a = dlim_regressor.predict(val_data.data[:,:-1], detach=True)
model_no = DLIM(n_variables = train_data.nb_val, hid_dim = 32, nb_layer = 0)
dlim_no = DLIM_API(model=model_no, flag_spectral=False)
losses = dlim_no.fit(train_data, test_data, lr = 1e-3, nb_epoch=300, batch_size=32, emb_regularization=0, \
save_path= model_save_path)
fit_no, var_no, lat_no = dlim_no.predict(val_data.data[:,:-1], detach=True)
score = pearsonr(fit_a.flatten(), val_data.data[:, [-1]].flatten())[0]
print(score)
score_no = pearsonr(fit_no.flatten(), val_data.data[:, [-1]].flatten())[0]
print(score_no)
fig, (ax, bx, cx, dx) = plt.subplots(1, 4, figsize=(8, 2))
data_simulated.plot(ax)
dlim_regressor.plot(bx, data)
for xx in [ax, bx, cx, dx]:
for el in ["top", "right"]:
xx.spines[el].set_visible(False)
# Plot the a00verage curve
r1 = spearmanr(dlim_regressor.model.genes_emb[0].detach(), data_simulated.A)[0]
r2 = spearmanr(dlim_regressor.model.genes_emb[1].detach(), data_simulated.B)[0]
print(pearsonr(lat_a[:, 0], val_data[:, -1]))
cx.text(dlim_regressor.model.genes_emb[0].detach().numpy().min(), data_simulated.A.max(), f"$\\rho={r1:.2f}$", c="C0")
cx.text(dlim_regressor.model.genes_emb[1].detach().numpy().min(), data_simulated.A.max() - 1, f"$\\rho={r2:.2f}$", c="C1")
cx.scatter(dlim_regressor.model.genes_emb[0].detach(), data_simulated.A, c="C0", s=3)
cx.scatter(dlim_regressor.model.genes_emb[1].detach(), data_simulated.B, c="C1", s=3)
cx.set_xlabel("$\\varphi_1$ | $\\varphi_2$")
cx.set_ylabel("$\\phi_1$| $\\phi_2$")
dx.scatter(val_data.data[:, [-1]].flatten(), fit_no.flatten(), c="grey", s=3)
dx.scatter(val_data.data[:, [-1]].flatten(), fit_a.flatten(), c="orange", s=3)
dx.text(val_data.data[:, [-1]].flatten().min(), fit_no.flatten().max(), f"$\\rho={score_no:.2f}$", c="grey")
dx.text(val_data.data[:, [-1]].flatten().min(), fit_a.flatten().max() - 0.6, f"$\\rho={score:.2f}$", c="orange")
dx.set_xlabel("F")
dx.set_ylabel("$\\hat F$")
# plt.suptitle(type_f)
plt.tight_layout()
plt.savefig("./img/fig2_" + str(type_f) + ".png", dpi=300, transparent=True)
plt.show()
spectral gap = 0.4233999252319336
spectral gap = 0.5134989023208618
0.9820337031758801
0.728135706461819
PearsonRResult(statistic=0.12619312824536638, pvalue=0.03824348486225553)
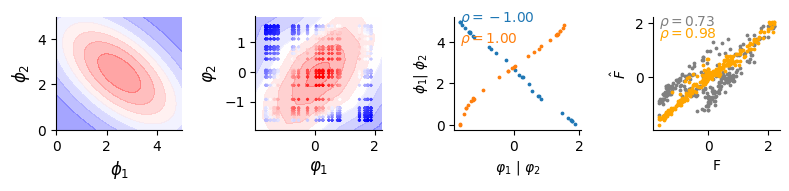
Biomechanistic model
[ ]:
type_f = "bio"
nb_var = 30
data_simulated = Simulated(nb_var, type_f)
data = Data_model(data=pd.DataFrame(data_simulated.data), n_variables=2)
model_save_path = None
# train_id = choice(range(data.data.shape[0]), int(data.data.shape[0]*0.7), replace=False)
# val_id = [i for i in range(data.data.shape[0]) if i not in train_id]
# train_data = data.subset(train_id)
# val_data = data.subset(val_id)
seed(45)
train_id_all = choice(range(data.data.shape[0]), int(data.data.shape[0]*0.7), replace=False)
seed(45)
train_id = choice(train_id_all, int(len(train_id_all)*0.9), replace=False)
test_id = [i for i in train_id_all if i not in train_id]
val_id = [i for i in range(data.data.shape[0]) if i not in train_id_all]
train_data = data.subset(train_id)
test_data = None #data.subset(test_id)
val_data = data.subset(val_id)
model = DLIM(n_variables = train_data.nb_val, hid_dim = 32, nb_layer = 0)
dlim_regressor = DLIM_API(model=model, flag_spectral=True)
losses = dlim_regressor.fit(train_data, test_data , lr = 1e-3, nb_epoch=300, batch_size=32, emb_regularization=0.001, \
save_path= model_save_path)
fit_a, var_a, lat_a = dlim_regressor.predict(val_data.data[:,:-1], detach=True)
model_no = DLIM(n_variables = train_data.nb_val, hid_dim = 32, nb_layer = 0)
dlim_no = DLIM_API(model=model_no, flag_spectral=False)
losses = dlim_no.fit(train_data, test_data, lr = 1e-3, nb_epoch=300, batch_size=32, emb_regularization=0.001, \
save_path= model_save_path)
fit_no, var_no, lat_no = dlim_no.predict(val_data.data[:,:-1], detach=True)
score = pearsonr(fit_a.flatten(), val_data.data[:, [-1]].flatten())[0]
print(score)
score_no = pearsonr(fit_no.flatten(), val_data.data[:, [-1]].flatten())[0]
print(score_no)
fig, (ax, bx, cx, dx) = plt.subplots(1, 4, figsize=(8, 2))
data_simulated.plot(ax)
dlim_regressor.plot(bx, data)
for xx in [ax, bx, cx, dx]:
for el in ["top", "right"]:
xx.spines[el].set_visible(False)
# Plot the a00verage curve
r1 = spearmanr(dlim_regressor.model.genes_emb[0].detach(), data_simulated.A)[0]
r2 = spearmanr(dlim_regressor.model.genes_emb[1].detach(), data_simulated.B)[0]
print(pearsonr(lat_a[:, 0], val_data[:, -1]))
cx.text(dlim_regressor.model.genes_emb[0].detach().numpy().min(), data_simulated.A.max(), f"$\\rho={r1:.2f}$", c="C0")
cx.text(dlim_regressor.model.genes_emb[1].detach().numpy().min(), data_simulated.A.max() - 1, f"$\\rho={r2:.2f}$", c="C1")
cx.scatter(dlim_regressor.model.genes_emb[0].detach(), data_simulated.A, c="C0", s=3)
cx.scatter(dlim_regressor.model.genes_emb[1].detach(), data_simulated.B, c="C1", s=3)
cx.set_xlabel("$\\varphi_1$ | $\\varphi_2$")
cx.set_ylabel("$\\phi_1$| $\\phi_2$")
dx.scatter(val_data.data[:, [-1]].flatten(), fit_no.flatten(), c="grey", s=3)
dx.scatter(val_data.data[:, [-1]].flatten(), fit_a.flatten(), c="orange", s=3)
dx.text(val_data.data[:, [-1]].flatten().min(), fit_no.flatten().max(), f"$\\rho={score_no:.2f}$", c="grey")
dx.text(val_data.data[:, [-1]].flatten().min(), fit_a.flatten().max() - 0.6, f"$\\rho={score:.2f}$", c="orange")
dx.set_xlabel("F")
dx.set_ylabel("$\\hat F$")
# plt.suptitle(type_f)
plt.tight_layout()
plt.savefig("./img/fig2_" + str(type_f) + ".png", dpi=300, transparent=True)
plt.show()
spectral gap = 0.9606298208236694, so we initialize phenotypes randomly
spectral gap = 0.9579210877418518, so we initialize phenotypes randomly
0.9984404565534528
0.9985161830492272
PearsonRResult(statistic=0.6832004518304313, pvalue=1.813148217940923e-38)
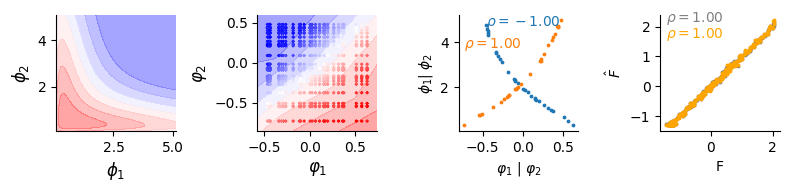
[ ]: